
库存扣减的那些事
常见问题
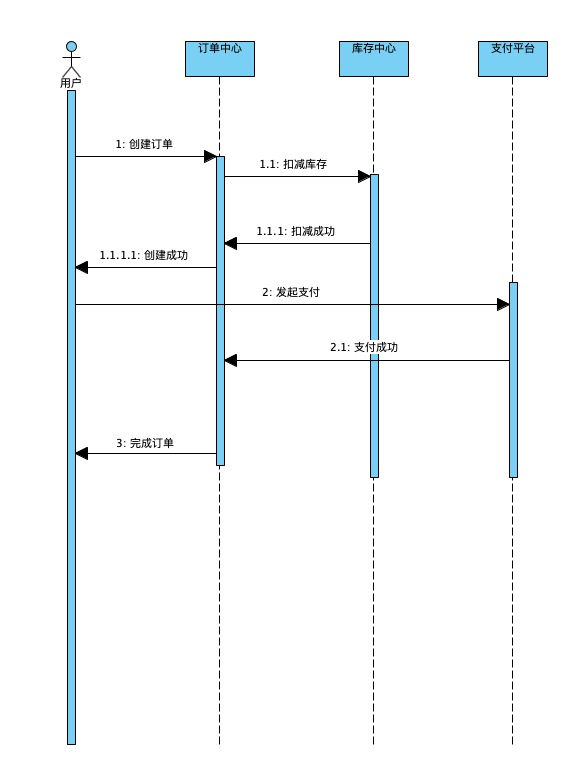
场景
- 平时我们网购下单,存在一些商品下单后支付成功,还有一些场景可能最后没有支付成功
问题:系统何时减库存
- 用户下单时扣减?
- 用户支付完成时扣减?
常见扣减方式
下单减库存
- 用户下单成功,扣减库存
- 特征
- 方式简单,控制最精确,通过数据库事务机制控制商品库存,不会出现超卖
- 问题
- 正常情况下,用户下单后一般会很大概率付款,不会有大问题。但是可能会有黄牛刷单的风险,可以做到无风险疯狂占用库存
支付减库存
- 用户下单后,并不立即扣减,而是用户完成支付后,才真正扣减库存,库存一直留给真正付款的用户

- 特征
- 避免黄牛 or 恶意下单
- 问题
- 并发高的情况下,用户下单后可能会出现付不了款(超卖问题)
- 超卖解决办法
- 商家允许的情况下,通过补货来解决
- 商家不允许的情况下,提示库存不足,不能完成支付
- 超卖解决办法
- 并发高的情况下,用户下单后可能会出现付不了款(超卖问题)
预扣库存(典型的预扣库存方案)
- 用户下单后,库存保留一定的时间(比如预售:30分钟),超过时间未付款,库存自动释放,留给其他用户继续购买
- 特征
- 下单时,预减库存,检测库存是否有充足
- 充足,扣减库存
- 不足,下单失败,提醒用户
- 支付完成时,校验订单有效性
- 订单未过期,支付成功
- 订单过期,其实库存已经释放,给用户退款
- 订单未过期,支付成功
- 下单时,预减库存,检测库存是否有充足
- 问题
- 虽然设置了库存的保留时间,但是用户可以在释放库存后再次钱柜,或者一次抢购大量库存抢占
- 并不能彻底解决超卖问题,我们目前都是使用第三方支付,没办法在订单到期释放库存的时候一定完成了付款,在释放库存和支付之间的临界值,假如出现并发,很可能还是导致超卖,但是这种是非常极端的场景
- 解决办法
- 一般秒杀情况下,商品都是爆款(可以理解为”抢到就是赚到”),下单后不付款情况很少,同时商家对于库存有严格的限制,”下单减库存”更加合理,同时该方式对比其他两种场景来说,逻辑上更加简单,性能上占有优势。
- 如何保障一致性?
- 根本目的就是保证数据库中库存字段对应的数值不能小于0!
- 常见解决方案
- 系统中通过事务来判断,保证扣减后数据不为负数,否则回滚
- 设置数据库字段数据为无符号证书,通过扣减是,字段值小于零触发sql语句报错
- update stock set 剩余库存 = 当前剩余库存-扣减库存 where 当前剩余库存-扣减库存 >= 0 实现比乐观锁更乐观的一种控制
先看一个库存扣减的设计
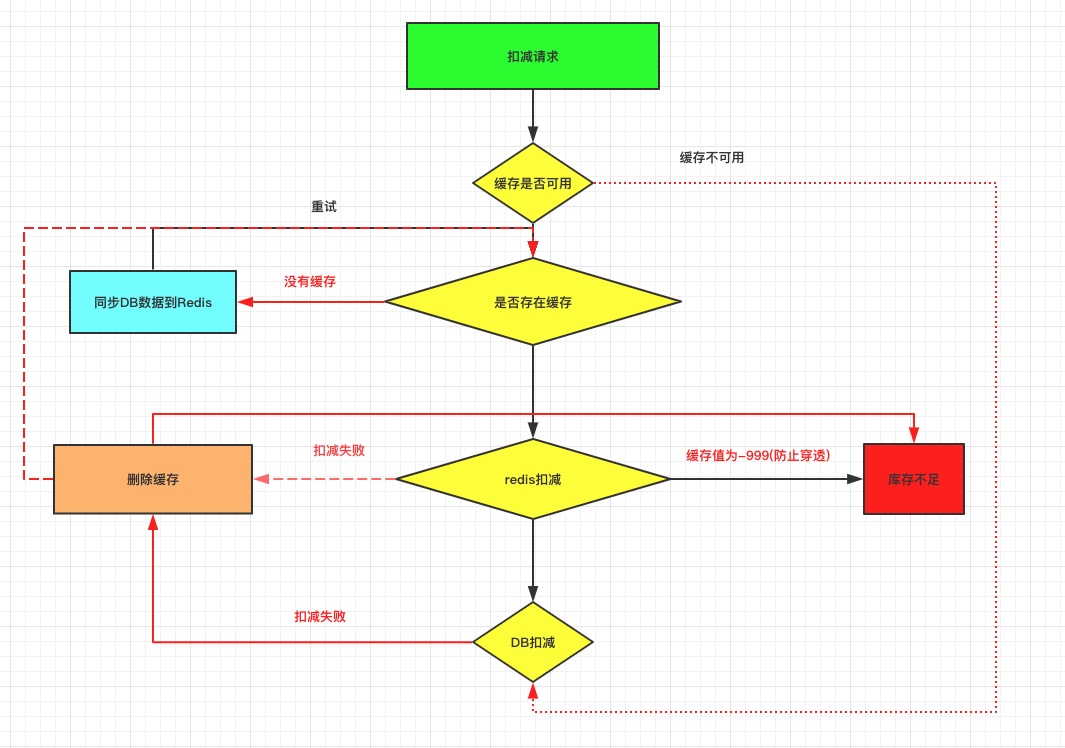
- 简单描述下图中的设计,先扣减缓存,缓存扣减成功扣减db,若缓存扣减成功,db扣减失败,上锁同步,如果发现库存为0,将缓存设置为-999,防止缓存穿透,如果缓存扣件失败,也直接上锁同步db
- 如果你觉得这个还不够复杂,等等,你是不是还忽略了一个问题,这个仅仅只是库存扣减,还没有涉及退款,超时等库存的回补操作,这个设计在分布式场景下,复杂度已经很高了
具体问题具体分析
- 我们在库存扣减设计中核心要解决的问题是什么?
- 库存扣减环节中,主要解决的问题是”并发写”
- 写在哪里?
- 缓存 or 数据库~
- 缓存中扣减库存
- 解决的是性能问题,复杂场景的关系映射不能很好支持,但是不支持事务
数据库中扣减
- 特性
- 基于Mysql数据存储的特性,同一个sku的库存扣减肯定是在同一行,会有大量的线程竞争InnoDB行锁,并发越高,等待线程就越多,TPS会下降,系统的整体RT就会跟着上升,严重影响到数据库的吞吐量
- 问题
- 常见的电商场景中,单个热点商品会影响整个数据库的性能,导致0.01%的商品影响99.99%商品的售卖。
解决办法
热点隔离(热点商品库,非热点商品库)
- 热点商品隔离到热点数据库中,但也带来问题,热点数据动态迁移和单独数据库维护等等问题,而且没有彻底解决并发锁的问题!!!
应用层排队
- 按照商品纬度设置队列排队,减少同一台机器对数据库同一行进行操作的并发度,同时也控制单个商品占用数据库连接的数量,防止热点商品占用太多的数据库连接
- 数据库层排队(修改MySql源代码)
- 机器数过多的情况下,应用层只是做到了单机排队,控制的并发能力有限。阿里数据库团队开发了针对Mysql的InnoDB层上的补丁程序(patch),可以在数据库层面对单行记录做到并发排队。
- 其他
- InnoDB内部存在死锁检测,MySql server 和 InnoDB的切换也会比较消耗性能,阿里数据库团队做了很多该方面的优化。COMMIT_ON_SUCCESS 和 ROLLBACK_ON_FAIL的补丁程序,配合在SQL里面添加hint(https://blog.csdn.net/fromdw/article/details/6653882),在事务里不需要等待应用层提交(COMMIT),而在数据库执行完最后一条SQL后,直接根据TRAGET_AFFECT_ROW的结果进行提交或回滚,可以减少网络等待时间(平均约0.7ms)。
该种方式,TPS在高并发下,从原始的150飙升到8.5w,提升近566倍!最新数据未知~
- InnoDB内部存在死锁检测,MySql server 和 InnoDB的切换也会比较消耗性能,阿里数据库团队做了很多该方面的优化。COMMIT_ON_SUCCESS 和 ROLLBACK_ON_FAIL的补丁程序,配合在SQL里面添加hint(https://blog.csdn.net/fromdw/article/details/6653882),在事务里不需要等待应用层提交(COMMIT),而在数据库执行完最后一条SQL后,直接根据TRAGET_AFFECT_ROW的结果进行提交或回滚,可以减少网络等待时间(平均约0.7ms)。
- 特性
库存扣减的核心到底在哪里
- 通过上面的分析我们可以得出一个结论
- 在上面举出的复杂例子中,缓存起到的作用,其实跟偏向于做了一层限流,防止流量都压到数据库上
- 库存扣减的瓶颈不在应用层面,而在于数据库层面
数据库能做哪些优化
I: 关闭死锁检测,提高并发处理性能
对于秒杀/热卖商品这种情况,通过认真的分析,可以得出这种情况的特点,首先是很直接,其次是很暴力,正常的业务死锁会变成超时,最后是不治标,除掉老大,还有老二,问题的症结没有解决,这时候究竟该如何解决呢?经过不断努力,得出了第一种解决方法关掉死锁检测。II:修改源代码,将排队提到进入引擎层前,降低引擎层面的并发度。
如果请求一股脑的涌入数据库,势必会由于争抢资源造成性能下降,通过排队,让请求从混沌到有序,从而避免数据库在协调大量请求时过载。
对于在固定的硬件条件下、每个系统都有一个对应的状态最优值,那么在InnoDB的线程数下,将排队队列提到进入引擎层前,这样就能够很好的解决在性能方面具有很好的提高。III:组提交,降低server和引擎的交互次数,降低IO消耗,请求合并:甲买了一个商品,乙也买了同一个商品,与其把甲乙当做当做单独的请求分别执行一次商品库存减一的操作,不如把他们合并后统一执行一次商品库存减二的操作,请求合并的越多,效率提升的就越大。
根据前面的排队技术,利用多线程并发下,InnoDB内部要做死锁检测等操作,会对性能影响及其严重,明确的串行事务,则server层串行,Group commit减少引擎执行次数,让性能最佳优。IV:目前的一些云上数据库解决方案是一种不错的选择
写在最后
- Redis只是解决性能问题,数据库才是解决库存一致性问题
- 没有万能的系统,任何算法和架构都顶不住巨大的流量,限流是万精油!